AsiaTechDaily – Asia's Leading Tech and Startup Media Platform


The “Operational Ceiling”: Why Infrastructure, Not Intelligence, Is AI’s New Bottleneck
As production AI requests hit a 5% failure rate, the focus is shifting from model parameters to infrastructure resilience and unified observability.
For much of the past two years, the artificial intelligence industry has operated on a relatively simple assumption: better models would solve most problems. The race revolved around leaderboard rankings, benchmark performance, context-window expansion, reasoning capabilities, and multimodal sophistication. Each successive model release promised sharper intelligence, lower hallucination rates, and increasingly human-like interactions. But inside enterprise production environments, a different reality is beginning to emerge. AI systems are not primarily failing because models lack intelligence. They are failing because the infrastructure around them is becoming too complex to operate reliably at scale.
According to Datadog’s State of AI Engineering 2026 report, nearly one in twenty AI requests now fails in production environments. More significantly, the majority of those failures are not caused by hallucinations or reasoning breakdowns, but by far more conventional operational issues: capacity limits, concurrency spikes, rate limits, retries, and infrastructure bottlenecks.
The findings signal an important turning point for the AI industry. The central challenge is no longer simply building smarter models. It is building systems capable of running those models consistently, securely, and economically in production.
In many ways, AI may now be entering the same operational phase that cloud computing experienced more than a decade ago: a transition where programmability created enormous opportunity, but also introduced unprecedented infrastructure complexity.
In a conversation with AsiaTechDaily, Yadi Narayana, Field CTO Asia Pacific and Japan at Datadog, said the industry’s competitive dynamics are already shifting away from raw model intelligence toward operational execution.
“The centre of gravity in AI is moving from model performance alone to whether organisations can operate AI systems reliably, securely and cost-effectively in production,” Narayana said.
“That shift matters because enterprises are no longer building around a single model or isolated use case. They are putting AI into live products, workflows and customer-facing systems, where uptime, latency, cost, safety and governance matter just as much as raw model quality.”

The implication is increasingly difficult to ignore. The next era of AI competition may not be won by companies with the largest models, but by those with the strongest operational maturity.
Mapping AI’s 5% Failure Rate
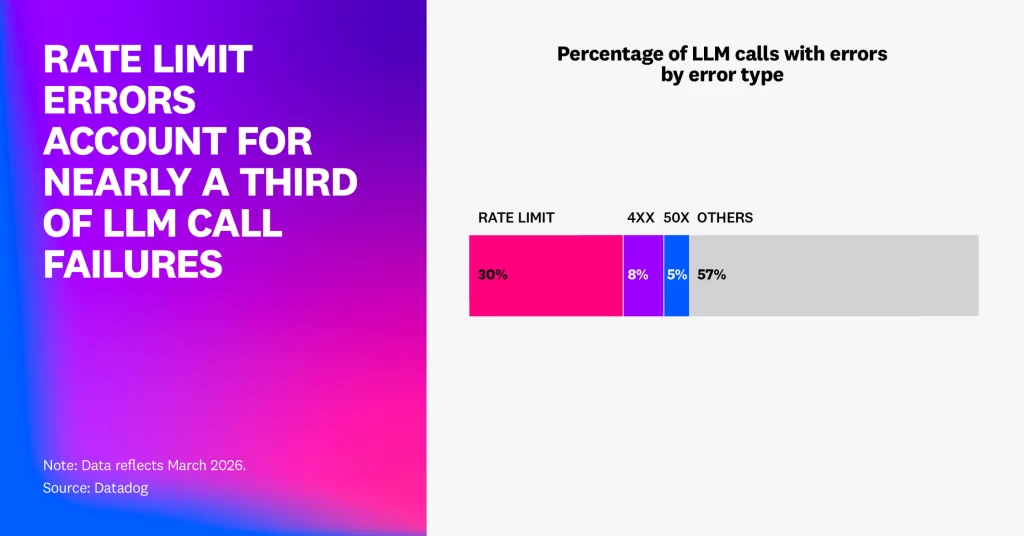
Datadog’s report offers one of the clearest snapshots yet of what large-scale AI deployment actually looks like inside production systems. The company analyzed anonymized telemetry from thousands of customers using large language models in live enterprise environments. The data revealed that approximately 5% of all LLM calls generated errors in February 2026. Of those failures, nearly 60% were tied to exceeded rate limits and capacity ceilings.
In March 2026, rate-limit errors alone accounted for nearly 8.4 million failed requests across Datadog’s dataset. That distinction matters because it reframes the industry’s understanding of AI risk. For much of the generative AI boom, public discourse focused heavily on model hallucinations, bias, and reasoning limitations. But Datadog’s findings suggest that enterprises scaling AI workloads are increasingly encountering a different category of problem entirely: operational fragility.
“In other words, AI is now hitting operational limits, not model limits,” Narayana said. “This is why AI competition is increasingly becoming a test of infrastructure readiness.”
The failures themselves resemble classic distributed systems problems:
- Request throttling,
- Concurrency exhaustion,
- Cascading retries,
- Latency spikes,
- Unstable service orchestration.
As AI agents execute increasingly complex workflows involving multiple tool calls, retrieval systems, and chained reasoning steps, the computational load placed on infrastructure expands dramatically.
What appears externally as a single AI interaction may internally involve numerous model calls, branching execution paths, retrieval pipelines, and autonomous loops operating simultaneously. That architectural shift is beginning to expose what could be described as AI’s “operational ceiling” — the point where the infrastructure surrounding AI systems becomes the limiting factor for scale.
Why Capacity Is Becoming the New Measure of AI Quality
One of the most important shifts identified in the report is the move away from single-model deployments toward what Datadog describes as “model portfolios.” More than 70% of organizations now use three or more AI models simultaneously, while the share using six or more models has nearly doubled over the past year.
Rather than selecting a single dominant provider, enterprises are increasingly routing workloads dynamically between OpenAI, Google Gemini, Anthropic Claude, and other models depending on latency requirements, cost structures, reasoning complexity, or task specialization.
This diversification improves flexibility, but it also creates an entirely new operational burden. Every additional model introduces different API structures, different latency characteristics, distinct failure patterns, separate governance requirements, additional evaluation overhead.
The result is that enterprises are gradually building distributed AI infrastructure stacks that resemble cloud-native systems more than standalone software applications. The challenge, then, is no longer simply determining which model performs best. It is determining whether the surrounding infrastructure can sustain reliable inference at scale.
That includes:
- Intelligent routing,
- GPU utilization management,
- Failover orchestration,
- Token optimization,
- Retry handling,
- Cross-provider observability.
Guillermo Rauch, CEO of Vercel, argued in the report that the next generation of AI failures will increasingly stem from operational blind spots rather than model shortcomings.
“The next wave of agent failures won’t be about what agents can’t do but what teams can’t observe,” Rauch said.
That observation points toward a broader industry transition. Inference quality alone is no longer sufficient. Operational visibility is becoming equally strategic.
The Hidden Cost of AI “Scaffolding”
The report also reveals another important dynamic inside enterprise AI systems: the rapid growth of hidden orchestration complexity. Modern AI applications are no longer simple prompt-response interfaces. They increasingly rely on heavily scaffolded agentic systems involving tool execution, policy instructions, retrieval pipelines, memory management, and multi-step workflows.
Datadog found that 69% of all input tokens processed across customer traces were consumed not by user queries, but by “system prompts” — internal instructions, policy layers, and operational guidance embedded within the application architecture itself. This effectively means the majority of AI computation inside production systems is now devoted to maintaining the scaffolding around the model rather than processing the end user’s request.
The implications are significant. As AI agents become more sophisticated, the supporting orchestration layers become increasingly expensive, latency-sensitive, and operationally fragile.
At the same time, token consumption is surging. Datadog found that average token usage more than doubled among median enterprise users and quadrupled among heavy users year-over-year.
That inflation creates what increasingly resembles a new category of technical debt: expensive, difficult-to-observe loops operating across distributed AI workflows. The report further found that prompt caching — one of the most effective methods for reducing cost and latency — remains underutilized despite widespread support across modern models.
Only 28% of supported LLM calls showed any cached token reuse. In practical terms, many organizations may be repeatedly paying to process nearly identical prompt structures because their orchestration systems are not optimized for operational efficiency.
The report also reveals a striking contradiction at the heart of the current agentic AI boom. While public narratives increasingly focus on autonomous multi-agent ecosystems, most production agents remain relatively monolithic. Datadog found that 59% of agentic requests still make only a single service call, while only 18% involve three or more services.
That gap suggests much of the industry remains in an intermediate phase: architecturally more complex than traditional applications, but not yet fully evolved into truly distributed agent systems.
AI’s Shift From Passive Monitoring to Active Operations
As AI systems become increasingly distributed and difficult to govern, observability itself is evolving.
Traditional monitoring systems were designed primarily to surface metrics and alerts for human operators. But AI infrastructure may require a more active operational model — one where AI assists directly in identifying, diagnosing, and remediating failures in real time. This transition is giving rise to what some industry players describe as an “Active SRE” era.
Datadog’s own approach reflects this shift through Bits AI SRE, which combines observability telemetry with AI-assisted reliability engineering workflows designed to help teams detect anomalies, investigate failures, and accelerate remediation. The broader significance extends beyond individual tooling products. The AI industry increasingly appears to be converging toward a future where operational control systems themselves become AI-assisted.
“AI is starting to look a lot like the early days of cloud,” said Yanbing Li, Chief Product Officer at Datadog. “The cloud made systems programmable but much more complex to manage. AI is now doing the same thing to the application layer.”
That comparison is particularly important because cloud computing ultimately created entire new software categories around orchestration, observability, security, and infrastructure automation. AI may now be triggering a similar platform transition.
Why the “Control Layer” Could Become the Next Strategic Battleground
The operational challenges emerging around enterprise AI have implications far beyond engineering teams.
For CTOs, the findings reinforce the growing importance of “Unified Observability” — the ability to monitor model behavior, infrastructure health, token economics, workflow execution, and security posture from a centralized operational layer. Without that visibility, enterprises risk scaling AI faster than they can govern it. The challenge becomes even more acute in Asia-Pacific markets, where AI adoption is accelerating unevenly across jurisdictions.
According to Narayana, markets such as Singapore are comparatively more advanced in governance and observability readiness, while other ASEAN economies are pushing deployments into production faster than their operational maturity may support.
That creates growing risks around reliability, compliance fragmentation, token-cost visibility, and infrastructure coordination across multi-market deployments.
For investors, meanwhile, the report highlights a potentially important strategic shift in the AI ecosystem itself.
Much of the first wave of generative AI investment centered around model providers and foundational research labs. But as operational bottlenecks intensify, value may increasingly accrue to what could be described as the “control layer” of AI:
- observability platforms,
- orchestration systems,
- routing infrastructure,
- governance frameworks,
- cost optimization engines,
- and AI operations tooling.
These systems increasingly determine whether enterprise AI deployments can scale sustainably.
Looking ahead, Narayana argued that the companies that successfully scale AI will be the ones that stop treating AI as a standalone innovation experiment and start operating it like production infrastructure.
“The companies that scale AI successfully will be the ones that stop treating AI as an isolated innovation project and start treating it as a production system,” Narayana told AsiaTechDaily.
“It will not come down to tooling, architecture or internal capability in isolation. It will come down to whether those three things work together: architecture that supports multi-model and agentic systems, tooling that makes those systems observable and governable and operating models that align engineering, data, security, product and finance teams around the same outcomes.
In practice, leaders will know where every token, GPU hour and model call is going, what value it creates and which workloads should be prioritised when capacity is constrained. Those that do not will find themselves constrained by outages, runaway costs and governance concerns, regardless of which models they choose.
As systems become more agentic, the challenge is no longer just monitoring an API call; it is understanding the full chain of reasoning, tool use, infrastructure dependency and user impact.
Ultimately, the winners will be organisations that combine experimentation with control. They will keep innovating with new models and agents, but they will also know how those systems behave in production, what they cost, how they fail and whether they are delivering measurable business value.
The organisations that struggle will be those that scale AI faster than they can observe, govern and optimise it,” he added.
For years, the defining question in AI was whether models could become intelligent enough to perform useful work. That question is rapidly being replaced by another: Can enterprises operate AI systems reliably enough to trust them at scale? The answer may define the next decade of the industry. The intelligence race is not over. Frontier model development will continue to push reasoning capability, multimodal performance, and agent autonomy forward.
But intelligence alone is no longer sufficient. As AI systems become increasingly multi-model, context-heavy, and operationally distributed, infrastructural resilience is emerging as the real determinant of production success. The companies most likely to succeed in the next phase of AI may not be those with the most advanced models — but those capable of governing complexity, maintaining reliability, controlling cost, and sustaining operational visibility across increasingly autonomous systems. The “intelligence phase” of AI may already be maturing. The operational phase is only beginning.
About Datadog
Datadog is a cloud monitoring, observability, and security platform that helps organizations monitor applications, infrastructure, logs, and AI systems in real time. Founded in 2010 and headquartered in New York, the company provides tools for infrastructure monitoring, application performance management (APM), log management, cloud security, and AI observability.
The company’s “State of AI Engineering 2026” report analyzes anonymized telemetry data from enterprise AI deployments to examine how organizations are operating large language models and agentic AI systems in production environments. Datadog has increasingly expanded its focus toward AI operations, observability, and reliability engineering as enterprises scale generative AI workloads.
Quick Takeaways
- Enterprise AI systems are increasingly failing due to infrastructure limitations rather than model intelligence issues.
- According to Datadog’s 2026 report, nearly 5% of production AI requests now fail, with most failures linked to rate limits, capacity ceilings, and operational bottlenecks.
- Companies are rapidly shifting from single-model deployments to multi-model AI architectures, adding significant operational complexity around routing, observability, governance, and cost management.
- AI applications are becoming heavily dependent on orchestration layers, retrieval systems, and agent workflows, creating what Datadog describes as growing “operational fragility.”
- Observability and AI operations tooling are emerging as critical infrastructure categories as enterprises struggle to scale AI reliably across production environments.
- The report suggests the next phase of AI competition may be determined less by model capability and more by operational maturity, infrastructure resilience, and governance readiness.
Similar Articles


